Data Studios
Data Studios is a unified platform where you can host a combination of container images and compute environments for interactive tertiary analysis using your preferred tools, like JupyterLab and RStudio Notebooks, or Visual Studio Code IDEs. Each data studio session is an individual interactive environment that encapsulates the live environment for dynamic data analysis.
On Seqera Cloud, the free tier permits only one running data studio session at a time. To run simultaneous data studios, contact Seqera for a Seqera Cloud Pro license.
Data Studios is currently in Public Preview.
Requirements
Before you get started, ensure you have the following:
- Valid credentials to access your cloud storage data resources.
- At least the Maintain role set of permissions.
- A compute environment with sufficient resources. This is highly dependent on the volume of data you wish to process, but it's recommended to have at least 2 CPUs allocated with 8192 MB of memory. See AWS Batch for more information about compute environment configuration.
Currently, Data Studios only supports AWS Batch compute environments that do not have Fargate enabled.
Overview
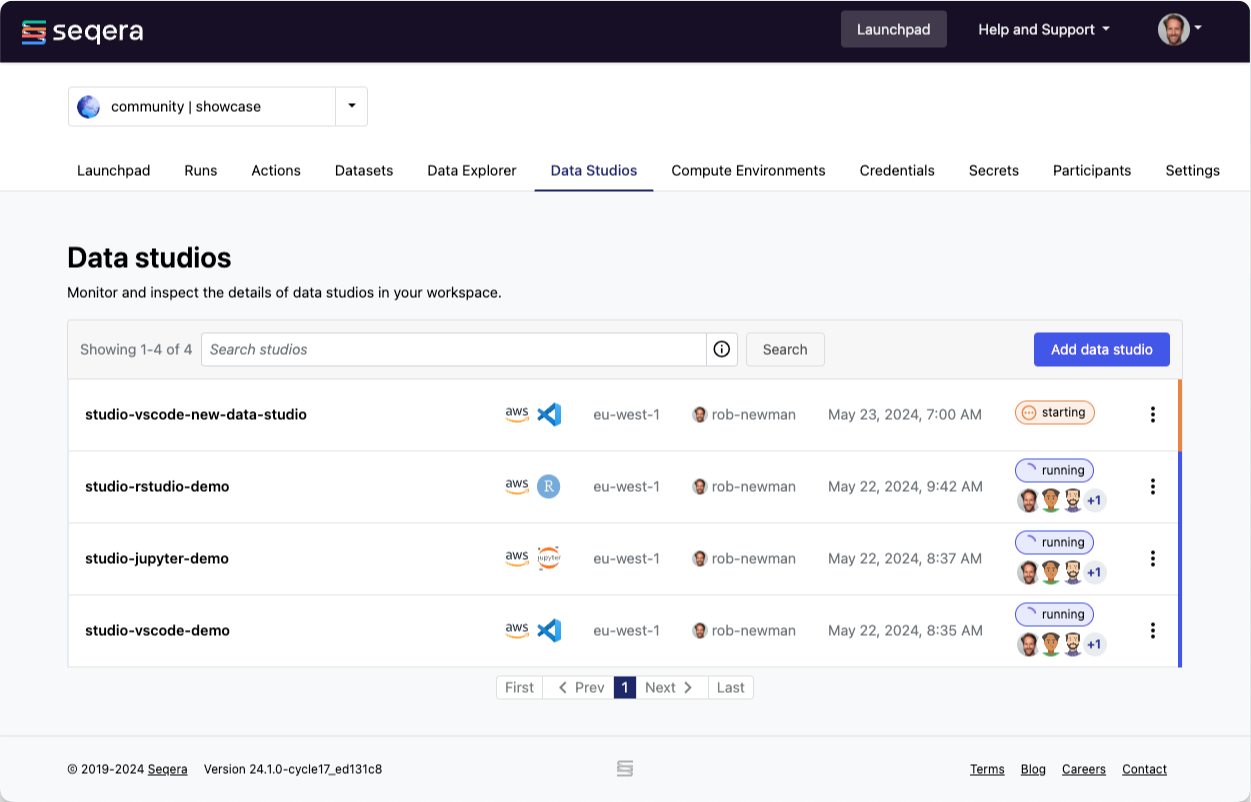
Select the Data Studios tab to view all data studios. The list includes the name, cloud provider, analysis template, region, author, creation date, and the status of each session. In this view, you can add a new data studio session, as well as start, stop, and connect to an existing data studio session. You can dynamically filter the list of data studio sessions using the search bar and searching by name (default), author username, or compute environment name. Selecting the session name opens a detailed view of the data studio, displaying configuration information.
Add a data studio
This functionality is available to users with the Maintain role and above.
- Select Add data studio.
- Select a container image template from the three options provided (JupyterLab, RStudio Server, or Visual Studio Code).
- Select a compute environment. Currently, only AWS Batch is supported.
- Mount data using Data Explorer: Select one or more datasets to mount. Datasets are mounted using the Fusion file system and are available at
/workspace/data/<dataset>. Mounted data doesn't need to match the compute environment or region of the cloud provider of the data studio. However, this might cause increased costs or errors. - Optional: Enter CPU and memory allocations. The default values are 2 CPUs and 8192 MB memory (RAM).
- Select Add.
You'll be returned to the Data Studios landing page that displays the list of data studios in your workspace. The data studio you created will be listed with the status stopped. You can inspect the configuration details by selecting the data studio session name.
By default, data studio sessions only have read permissions to mounted data paths. Write permissions can be added for specific cloud storage buckets during the compute environment configuration by defining additional Allowed S3 Buckets. This means that data can be written from the data studio session back to the cloud storage path(s) mounted. To stop potential data loss, only one data studio session per workspace can mount a unique data path. When adding a new data studio, data paths already mounted to other running data studios are unavailable. If a new file is uploaded to the cloud storage bucket path while a session is running, the file may not be available to the data studio session immediately.
About container image templates
Data Studios currently provides three container image templates: JupyterLab, RStudio Server, and Visual Studio Code. The image templates install a very limited number of packages when the data studio session container is built. Users have permission to install additional packages as needed.
JupyterLab
The default user is the root account. The following conda-forge packages are available by default:
pythonpipjedi-language-serverjupyterlabjupyter-collaborationjupyterlab-gitjupytextjupyter-dashipywidgetspandas[all]scikit-learnstatsmodelsitablesseaborn[stats]altairplotlyr-ggplot2nb_blackqgrid
To install additional Python packages, execute !pip install <packagename> commands in your notebook environment. Additional system-level packages can be installed in a terminal window using apt install <packagename>.
RStudio Server
The default user is the rstudio account and has sudo privileges. To install R packages, execute install.packages("<packagename>") commands in your notebook environment. Additional system-level packages can be installed in a terminal window using sudo apt install <packagename>.
Visual Studio Code
The default user is the root account. To install extensions, select Extensions. Additional system-level packages can be installed in a terminal window using apt install <packagename>.
Start a data studio
This functionality is available to users with the Maintain role and above.
A data studio needs to be started before you can connect to it. From the list in your workspace, select the three dots next to the status message for the data studio you want to start, then select Start. You can optionally change the configuration of the data studio, then select Start in new tab. A new browser tab will open that displays the startup state of the data studio. Once the data studio has successfully started running, you can connect to it. A data studio will run until it is stopped manually or it encounters a technical issue.
A data studio session consumes resources until it's stopped.
Once a data studio session is in a running state, you can connect to it, obtain the public link to the session to share with collaborators inside your workspace, and stop it.
Start an existing data studio as a new data studio
This functionality is available to users with the Maintain role and above.
You can use any existing data studio as the foundation for adding a new data studio. This functionality creates a clone of the data studio, including its checkpoint history, preserving any modifications made to the original data studio. When you create a data studio based in this way, future changes are isolated from the original data studio.
When adding a new data studio from an existing data studio or data studio checkpoint, the following fields are immutable:
- Data studio template
- Original data studio and checkpoint
- Compute environment
To add a new data studio from an existing stopped data studio, complete the following steps:
- In a workspace, select Data Studios.
- From the list of data studios in your workspace, select the three dots next to the status message for the data studio you want to start, then select Start as new. The Add data studio form opens.
- Optional: In the Add data studio form, customize the following fields:
- Data studio name
- Description: By default, the parent data studio name(s).
- Mounted data
- CPU
- Memory
- Select Add to add the new data studio.
Additionally, you can add a new data studio from any existing data studio checkpoint except the currently running checkpoint. From the data studio detail page, select the Checkpoints tab and in the Actions column, select Start as new data studio. This is useful for tertiary analysis experimentation without impacting the state of the original data studio.
Connect to a data studio
This functionality is available to all user roles excluding the View role.
To connect to a running data studio session, select the three dots next to the status message and choose Connect. A new browser tab will open containing the data studio environment.
An active connection to a data studio session will not prevent administrative actions that might disrupt that connection. For example, a data studio can be stopped by another workspace user while you are active in the session, the underlying credentials can be changed, or the compute environment can be deleted. These are independent actions and the user in the session won't be alerted to any changes - the only alert will be a server connection error in the active session browser tab.
Once connected, the data studio session list will update to display the status of running and any connected user will have their avatar displayed under the status in both the list of Data Studios and in each data studio session detail page.
Collaborate in a data studio
This functionality is available to all user roles excluding the View role.
To share a link to a running data studio with collaborators inside your workspace, select the three dots next to the status message for the data studio you want to share, then select Copy data studio URL. Using this link, other authenticated users can access the session directly.
Collaborators need valid workspace permissions to connect to the running data studio.
Stop a data studio
This functionality is available to all user roles with the Maintain role and above.
To stop a running data studio session, select the three dots next to the status message and then select Stop. The status will change from running to stopped. When a data studio session is stopped, the compute resources it's using are deallocated. You can stop a session at any time, except when it is starting.
Stopping a running data studio creates a new checkpoint.
Restart a stopped data studio
This functionality is available to all user roles with the Maintain role and above.
When you restart a stopped data studio session, the session uses the most recent checkpoint.
Start a new data studio from a checkpoint
This functionality is available to all user roles with the Maintain role and above.
You can start a new data studio from an existing stopped data studio. This will inherit the history of the parent data studio checkpoint state. From the list of stopped data studios in your workspace, select the three dots next to the status message for the data studio and select Start as new. Alternatively, from the data studio detail page select the Checkpoints tab and choose a non-running checkpoint to start a new data studio from by clicking the three dots in the Actions column and selecting Start as new.
Delete a data studio
This functionality is available to all user roles with the Maintain role and above.
You can only delete a data studio when it's stopped. Select the three dots next to the status message and then select Delete. The data studio is deleted immediately and can't be recovered.
Data studio checkpoints
When you start a data studio session, it automatically creates a checkpoint. A checkpoint saves changes that you make to the data studio root filesystem and stores it in the compute environment's pipeline work directory in the .studios/checkpoints directory under a unique name.
Running data studios create a new checkpoint, or snapshot, every five minutes.
When you stop and start a data studio session, or start a new data studio session from a previously created checkpoint, changes such as installed software packages and configuration files are restored and made available in the data studio session. Changes made to mounted datasets are not included in a checkpoint.
Checkpoints can be renamed and the name has to be unique per data studio. Spaces in checkpoint names are converted to underscores automatically.
Checkpoint files in the compute environment work directory may be shared by multiple data studios. Each checkpoint file is cleaned up asynchronously after the last data studio referencing the checkpoint is deleted.
The cleanup process is a best effort and not guaranteed. Seqera attempts to remove the checkpoint, but it can fail—for example, if the compute environment credentials used do not have sufficient permissions to delete objects from storage buckets.
Data studio statuses
Data studios have the following possible statuses:
- starting: The data studio is initializing.
- running: When a data studio session is running, you can connect to it, copy the data studio URL, or stop it. In addition, the session can continue to process requests/run computations in the absence of an ongoing connection.
- stopping: The recently-running session is in the process of being stopped.
- stopped: When a session is stopped, the associated compute resources are deallocated. You can start or delete the data studio when it's in this state.
- errored: This state most often indicates that there has been an error starting the data studio session but it is in a stopped state. There might be errors reported by the session itself but these currently will be overwritten with a running status if the data studio session is still running. If you encounter an error with the Public-Preview release of Data Studios, please reach out to your Seqera account executive.
Troubleshooting
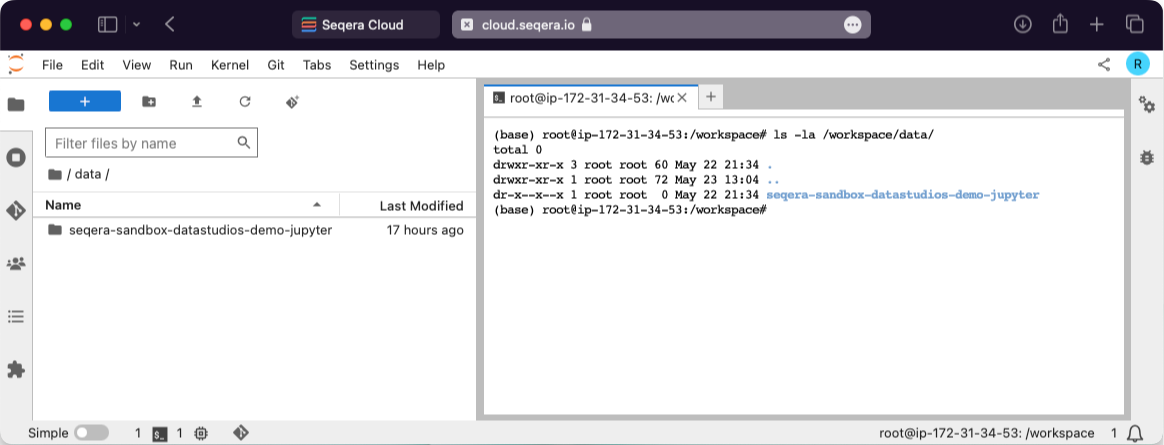
Viewing all mounted datasets
In your tertiary analysis environment, open a new terminal and type ls -la /workspace/data. This displays all the mounted datasets available in the current data studio.
My data studio is stuck in starting
If your data studio doesn't advance from starting status to running status within 30 minutes, and you have access to the AWS Console for your organization, check that the AWS Batch compute environment associated with the data studio session is in the ENABLED state with a VALID status. You can also check the Compute resources settings. Contact your organization's AWS administrator if you don't have access to the AWS Console.
If sufficient compute environment resources are unavailable, Stop your data studio and any others that may be running before trying again. If you have access to the AWS Console for your organization, you can terminate a specific data studio from the AWS Batch Jobs page (filtering by compute environment queue).
My data studio status is errored
The errored status is generally related to issues encountered when creating the data studio resources in the compute environment (e.g., invalid credentials, insufficient permissions, network issues). It can also be related to insufficient compute resources, which are set in your compute environment configuration. Contact your organization's AWS administrator if you don't have access to the AWS Console. Please also reach out to your account executive so we can investigate the issue.
My data studio can't be stopped
If you're not able to stop a data studio session, it's usually because the Batch job running the data studio failed for some reason. In this case, and if you have access to the AWS Console for your organization, you can stop the data studio from the compute environment screen. Contact your organization's AWS administrator if you don't have access to the AWS Console. Also contact your Seqera account executive so we can investigate the issue.
My data studio performance is poor
A slow or unresponsive data studio may be due to its AWS Batch compute environment being utilized for other jobs, such as running Nextflow pipelines. The compute environment is responsible for scheduling jobs to the available compute resources. Data Studio sessions compete for resources with the Nextflow pipeline head job and Seqera does not currently have an established pattern of precedence.
If you have access to the AWS Console for your organization, check the jobs associated with the AWS Batch compute environment and compare with its Compute resources settings.
What happens if the memory allocation of the data studio is exceeded?
The running container in the AWS Batch compute environment inherits the memory limits specified by the data studio configuration when adding or starting the data studio session. The kernel then handles the memory as if running natively on Linux. Linux can overcommit memory, leading to possible out-of-memory errors in a container environment. The kernel has protections in place to prevent this, but it can happen, and in this case, the process is killed. This can manifest as a performance lag, killed subprocesses, or at worst, a killed data studio session. Running data studio sessions have automated snapshots created every five minutes, so if the running container is killed only those changes made after the prior snapshot creation are lost.
All my datasets are read-only
By default, AWS Batch compute environments that are created with Batch Forge restrict access to S3 to the working directory only, unless additional Allowed S3 Buckets are specified. If the compute environment does not have write access to the mounted dataset, it will be mounted as read-only.
What happens when the allocated storage for the data studio is exceeded?
A data studio is allocated a 5GB overlay filesystem partition by default for installing software packages and other local configuration. This limit is irrespective of the boot disk size of the container. If you exceed the available storage space, you cannot reliably make local changes to the data studio container until you free up disk space.
Each time you stop and start a data studio, an additional 5GB allocation is provided. If you are experiencing a disk size limitation, as a workaround you can stop and restart the data studio.